
I18N看似是一个不太难的问题,每个人都可以通过短暂的思考就得到的一些方法:文本资源化,具体文本与逻辑解耦,运行时切换语言资源,巴拉巴拉巴拉。但是这个方案应可以应对项目功能的演化、文本规模的膨胀、性能与内存的优化需求么?
吐槽
每个苦难都来自对美好未来的盲目期许。
项目中的I18N历史演化
“历史遗留问题”是一个焚化炉,项目里但凡有技术上的疑问与质疑,只要往这个焚化炉里一扔,立刻销匿矛盾。
在项目初期,文本直接在各个系统的配置数据中保存和导出。
后来引入I18N方案,在配置数据表中指定哪些字段是I18N,并同时导出配置数据的结构说明文件,配置数据,以及I18N数据。配置数据与I18N由自动生成的key关联。因为具体的业务逻辑都运行在Lua中,所以导出I18N的数据也直接保存为UTF-8编码的Lua Table文件。在运行时,由加载具体数据的底层模块自动读取I18N的结构说明文件,根据配置数据中的key索引I18N文本后将key换成正确的文本信息。UI Window指定I18N的文本(和图片)组件,保存I18N key在Prefab上并导出I18N文本,UI Window运行初始化时从Lua Table读取静态的I18N文本。
这个方案有一个有点是业务逻辑透明使用I18N文本,全部改造工作由导出工具和底层模块完成。
一年半后的一天任务策划报告全部I18N失效,导出数据没问题但是所有界面显示不正常。排查过后发现是任务数据导出I18N条目过多,行数(5万+)以及数据量大于了单个Lua文件解析上限。马上准备应对策略:
- 文本拆分,导出工具自己做检查,当导出条目过多时自动拆分文件。
- 空文本不导出,这个可以极大缓解问题,推迟问题,但是不能解决问题。
因导出工具和导出流程的自身限制(VBA+数值策划兼职写导出工具),以及项目到达中后期时间节点的紧迫,所以放弃拆分文件这个有难点时间长的方案,采用不导出空文本的方案。
后面为了优化UI相关性能,看到UI的静态I18N没必要通过Lua来倒一手,所以在C#层面单独写了一个UI I18N的加载助手类,自己读取,减少Lua内存开销和Lua到C#的穿透开销。
到此就是项目最终使用的I18N方案了。那么I18N还有优化空间么?
I18N的数据特征
数据规模
到写文章时,项目里由配置表导出工具导出的I18N统计数据见下表(中文数据):
| I18N类别 | 数量(条) | 占用空间(utf16) | 占用空间(utf8) |
|---|---|---|---|
| 包含空白项 | 199438 | — | — |
| 去空白项 | 117321 | 8.3MB | 9.1MB |
| 除去Key以后的纯文本 | 117321 | 3.8MB | 4.6MB |
| 去重复值项 | 57232 | 2.8MB | — |
如上表数据,项目里有近一半I18N数据是空串,剩下一半中文本不重复的项又剩一半。造成这个原因的一方面是有大量空白key和重复的值,另一方面是我们在导出的大量I18N形式诸如task_template_task_complete_condition_task_target_1_comment_1000001="杀怪",这导致Key占据空间竟然跟文本差不多大。另一方面这个string key所占据的空间其实是两份,一份配置数据中的,一份是I18N中的。
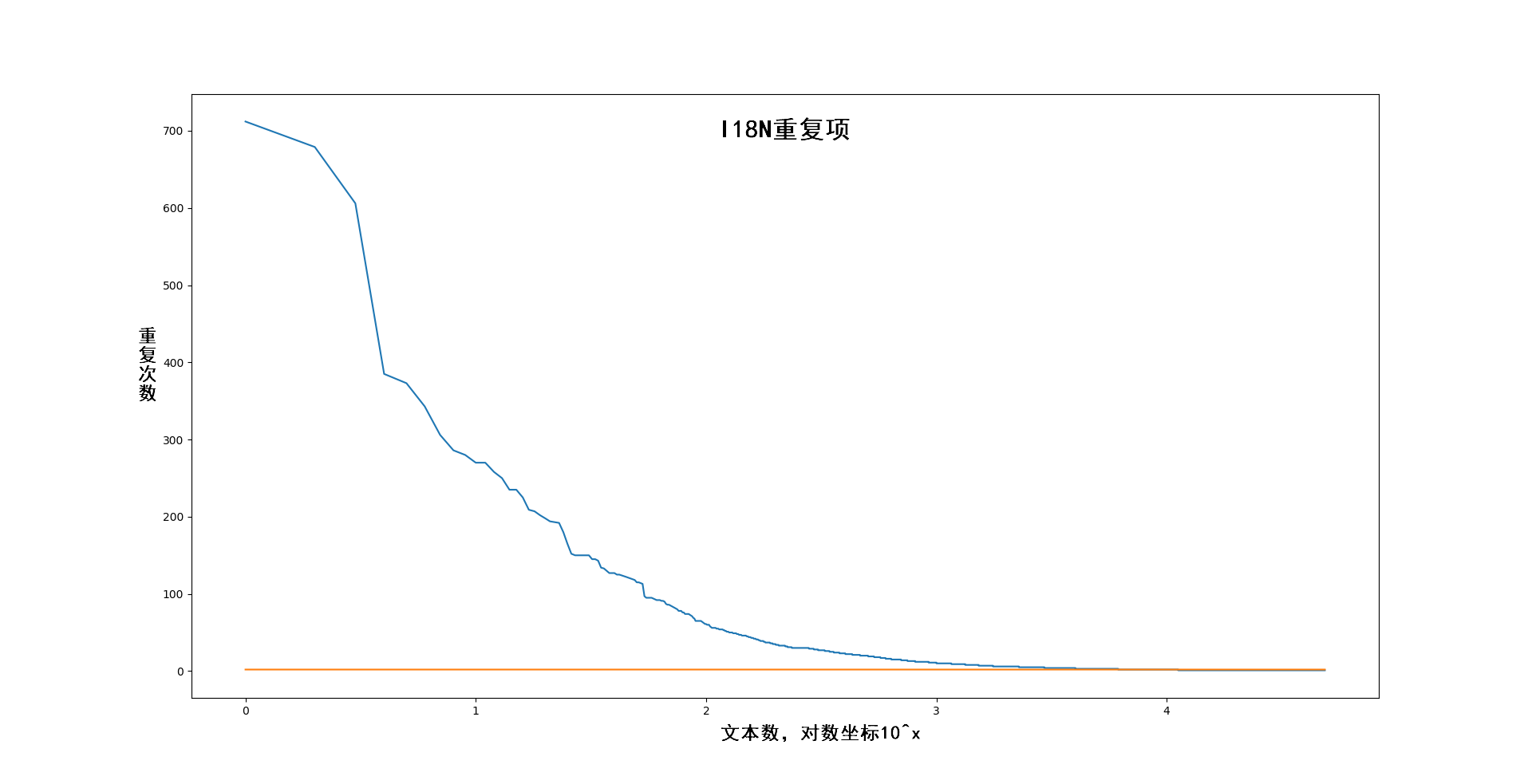
使用场景以及使用率
上文简单提到UI和配置数据中使用I18N的两个场景,但是不够细化,现统计分类如下:
“使用率”依赖采样流程,流程不同数据略有差距,只能做定性分析
|分类|采样使用率|
|:-|:-|
|UI静态I18N文本|15.28%|
|I18N说明文本|9.75%|
|动画I18N文本|2.01%|
|逻辑文本|72.96|
各分类使用文本的频数
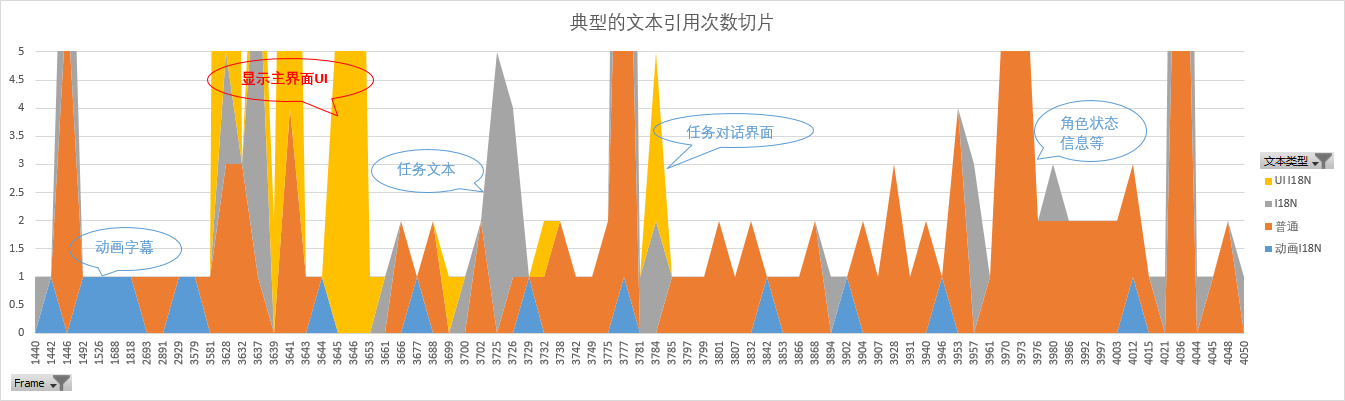 采样中I18N文本和逻辑文本的字符长度分布(非字节长度)
采样中I18N文本和逻辑文本的字符长度分布(非字节长度)
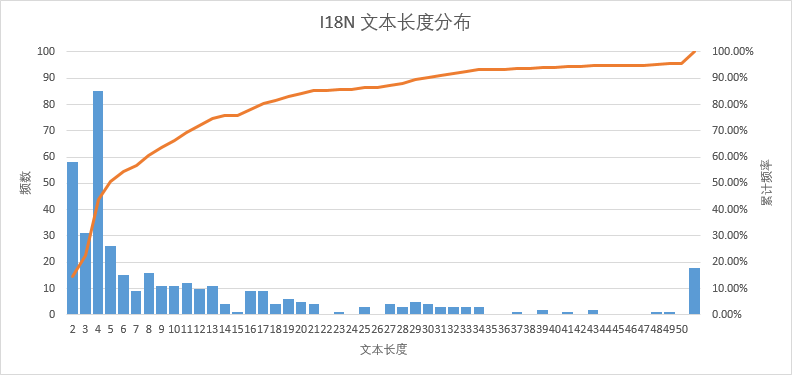
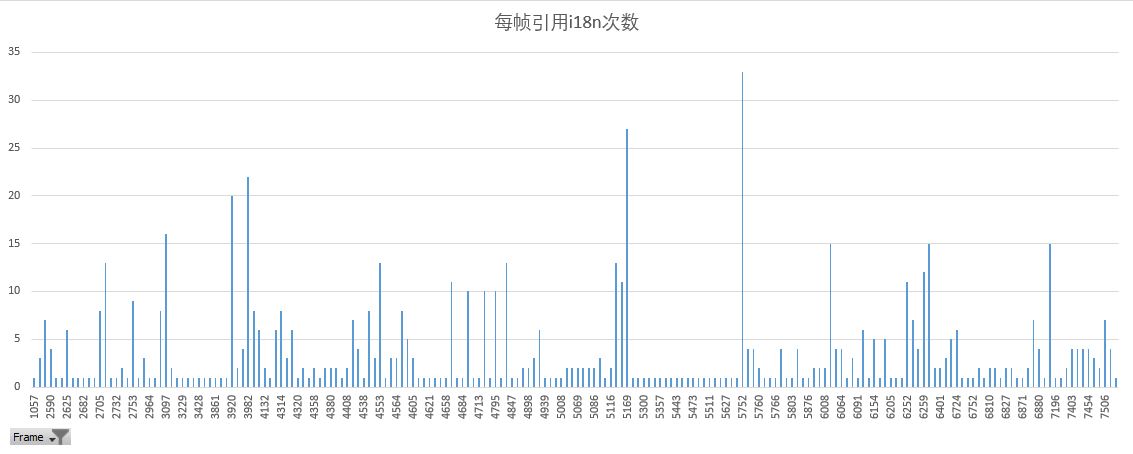
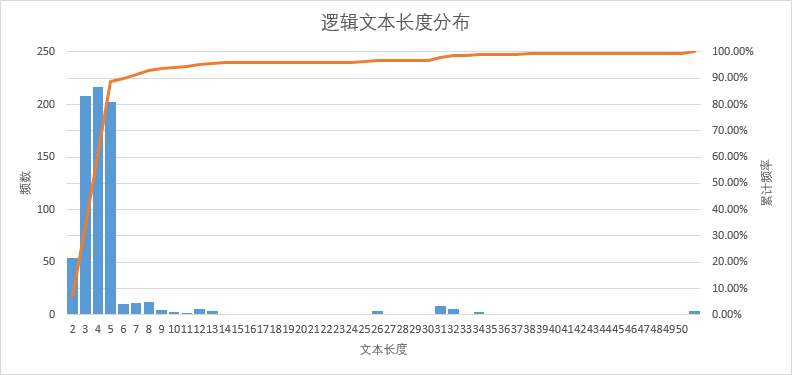 采样中I18N使用频数
采样中I18N使用频数
优化方案
根据前文统计的一些数据特征,可以得出一个简单的优化方案:
- 去掉重复的文本信息
- 简化I18N中的string key为int类型id
- 不一次性加载所有的文本信息,随用随读
- 不一次加载某一个id数据中所有的I18N文本
- Lua逻辑不直接设置I18N文本,减少Lua到C#的字符串穿透问题
倒数第二条是针对大量逻辑中,仅使用部分数据的I18N文本的问题。比如任务系统,对于不同的任务状态,逻辑里只处理对应状态下的文本。
最后一条是针对Lua使用的方面的,Lua层面大部分时候时不需要知道i18n具体是什么内容的,只需要把每个对应的值设置到UGUI Text Component中,这样还能解决一些Lua和C#的穿透问题。
tolua中,lua到C#或C#都要重新分配内存并复制以及做UTF-8到UTF-16的转码
镣铐
因为封包临近,以及之前所有配置数据都是使用的string key来定位I18N文本的,如果从导出工具方面改,策划同学来不及操作;如果从打包流程改增加自动替换所有key的过程则会遇到多次部分导出的UID一致性问题、本地编辑环境与手机包逻辑略有差异,所以暂时替换所有I18N key为UID有困难。另一个问题是上文演化过程中提及的,因为在Lua文本超解析上限而采取不导出空文本的策略,而具体业务中也有依赖文本为空的相关逻辑,所以不得不考虑还要存储missing key的信息。
使用二进制I18N文本
如果要去掉重复的文本信息,就要忽略原来设计中的各个逻辑分区(比如task的I18N,item的I18N),然后把所有文本存到一个文件里。如果想不一次加载所以文件,那么只好自己写sorted table的二进制文件。另一方面在不改变原有配置数据的结构与具体值的情况下,仅在底层转换,访问时先把原数据中string key求hash值1,然后拿这个hash值取索引I18N文本。基于这个思路,先设计一下文件结构:
| 文件头 | 标识头 | |||
| 索引头 | 索引个数 | 索引数据开始位置 | 索引数据大小 | |
| hash碰撞头 | 碰撞个数 | 碰撞数据开始位置 | 碰撞数据数据大小 | |
| 文本头 | 文本个数 | 文本数据开始位置 | 文本数据数据大小 | |
| 索引数据 | ||||
| 4 Byte | 4 Byte | |||
| hash code | 文本的偏移地址 | |||
| 碰撞数据 | ||||
| 4 Byte | 4 Byte | 4 Byte | n Byte | |
| size of self | hash code | 文本的偏移地址 | string key+’\0’ | |
| 文本数据 | ||||
| 4 Byte | n Byte | |||
| size of self | text+’\0’ |
I18N系统在初始化过程中,先把所有的碰撞数据和索引都加载进来。如上文统计,大概有1.6MB索引数据(或800kB有索引数据,400kB missing key数据),几乎没有碰撞数据。在具体引用文本时在通过Seek函数设置偏移地址并读取。一个优化方法是使用LRU按找offset来缓存文本内容。
对比一下原始Lua层操作I18N和修改后的操作I18N的差别,注释掉的是原有逻辑
function DataManager.GetData(scope, id)
local data = load_data_from_resource_manager(scope, id)
-- local i18n_define = load_data_from_resource_manager(scope)
-- for key, v in pairs(data) do -- The nested struct is not handled this example;
-- if i18n_define[key] do
-- data[key] = load_i18n_from_resource_manager(scope)[key]
-- end
-- end
end
function TextHelper.SetText(ui_text_component, text)
-- CShap.TextHelper.SetText(ui_text_component, text) -- text is i18n
local retcode = CShap.TextHelper.SetTextI18N(ui_text_component, hash(text)) -- text is i18n string key
if retcode ~= 0 then
CShap.TextHelper.SetTextI18N(ui_text_component, text)
end
end
local data = DataManager.GetData(scope, id)
TextHelper.SetText(ui_text_component, data.name)
读取性能相关
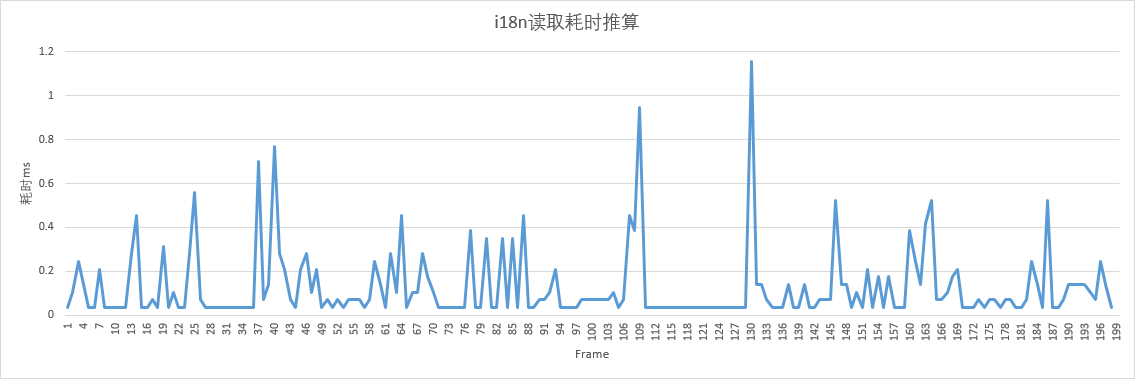
其实这个方案只是减少了常驻的I18N内存(虽然不大),但是增加了IO次数。通常的优化都是用内存换运行效率,我这里却反其道而行,一方面是想减少最I18N内存占用,一方面是想减少突发加载I18N时掉帧的问题。(现在项目的资源管理都是使用时才同步加载)看一组手机IO测试,数据来源于采样某一流程里所有用到的I18N信息,然后统一连续全部读取。
| 类别 | 测量序号 | 读取次数 | 总耗时 | 总缓存命中 | 平均每次耗时 | 总耗时/((1 - 缓存命中) * 读取次数) |
|---|---|---|---|---|---|---|
| win编辑器 | 1 | 705 | 16ms | 84.44% | 0.023ms | 0.145ms |
| VIVO X9 | 1 | 705 | 47ms | 84.44% | 0.067ms | 0.427ms |
| VIVO X9 | 2 | 705 | 24ms | 84.44% | 0.034ms | 0.218ms |
| VIVO X9 | 3 | 705 | 25ms | 84.44% | 0.035ms | 0.227ms |
| Meizu 16th | 1 | 705 | 23ms | 84.44% | 0.033ms | 0.209ms |
| Meizu 16th | 2 | 705 | 15ms | 84.44% | 0.021ms | 0.136ms |
| Meizu 16th | 3 | 705 | 11ms | 84.44% | 0.016ms | 0.100ms |
估算的IO实时耗时:
结语
这篇讨论有一点标题党,之前都没有谈及的一个局限性是这个I18N的优化依赖于业务层对调用接口的替换,即原来数据字段是I18N文本的,要使用新的接口才能减少Lua到C#穿透,而且这个替换还不能自动完成(逻辑调用比较深)。这个问题其实带来了程序方面的大量工作,效果也不是那么特别令人激动。
另一方面是前面数据统计文本特征中,有近90%的非I18N文本长度是极短,那么这样的文本从Lua到C#传递是不是可以按照固定buffer操作来进一步节省穿透GC。
最后,对于优化I18N读取时间方面,可以在接口层做异步加载,这样还能再减少掉帧的可能。