
本文主要对比分析Lua 5.1.5和LuaJit 2.1.0-beta3这两个版本lua虚拟机对于Table的实现以及测量它们各自的插入与删除表现。
测量设备和环境
- CPU: Intel i7-9700 @ 3.00GHz
- RAM 64GB
- Windows
为了方便编译Lua和Luajit虚拟机,最终的Banchmark是在WSL 1上使用GCC编译运行的。
- WSL 1 Ubuntu-18.04
- GCC version 7.5.0, -O2
内存消耗
Lua类型分类
Lua中常见的类型有boolean,number,string,function,table,userdata。在Lua虚拟机实现中又针对GC方式分为两类:TValue和GCObject。[^1]
其中boolean和number是TValue类型;string,function,table,userdata是GCObject,除此之外GCObject还有Proto,UpVal和lua_State(详见lua-5.1.5源文件lobject.h和lstate.h定义)。
Lua TValue的内存布局
- 因为Lua虚拟机是C语言开发的,无法直接实现继承和接口关系,所以在Lua虚拟机中大量使用union结构和宏来实现多态,下列图示水平向为union,纵向为内存增长。
TValue是Lua基础类型,其中值类型通过TValue字段n(Lua_Number)或b(boolean)直接使用,GCObject类型通过TValue字段gc间接引用。Lua脚本中local变量会首先是一个TValue,然后在通过字段tt确认具体是哪一种变量。
Luajit没有特意定义int tt字段用以区分变量类型,而是重用IEEE-754对于NAN特殊定义来实现类型区分的。这样做可以明显节省内存,尤其是对于数组,可以减少因内存对齐而造成的浪费(见Luajit源码lj_obj.h定义)。但是这样需要约定潜规则:
- Luajit指针只能使用低47bit(平台相关特性,虽然现在大部分没有问题)
- Luajit实现的位运算对于Number类型只能使用低32bit
其中TValue类型内存布局见下图。其中在Lua 5.1 64位虚拟机中TValue所占空间是16字节(Window/Linux的内存对齐)。
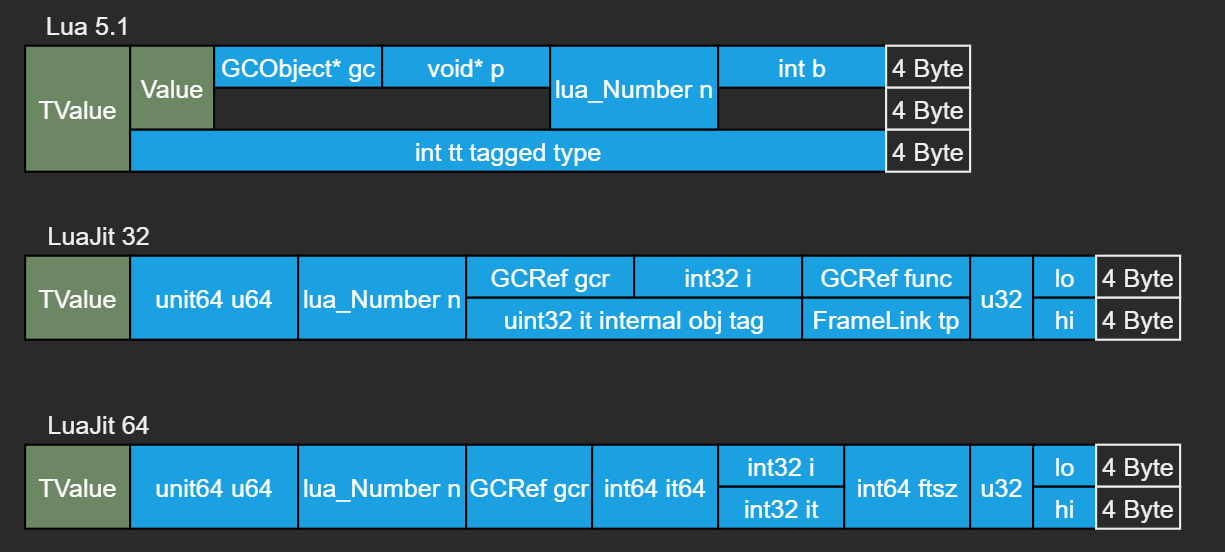
Lua Table的内存布局
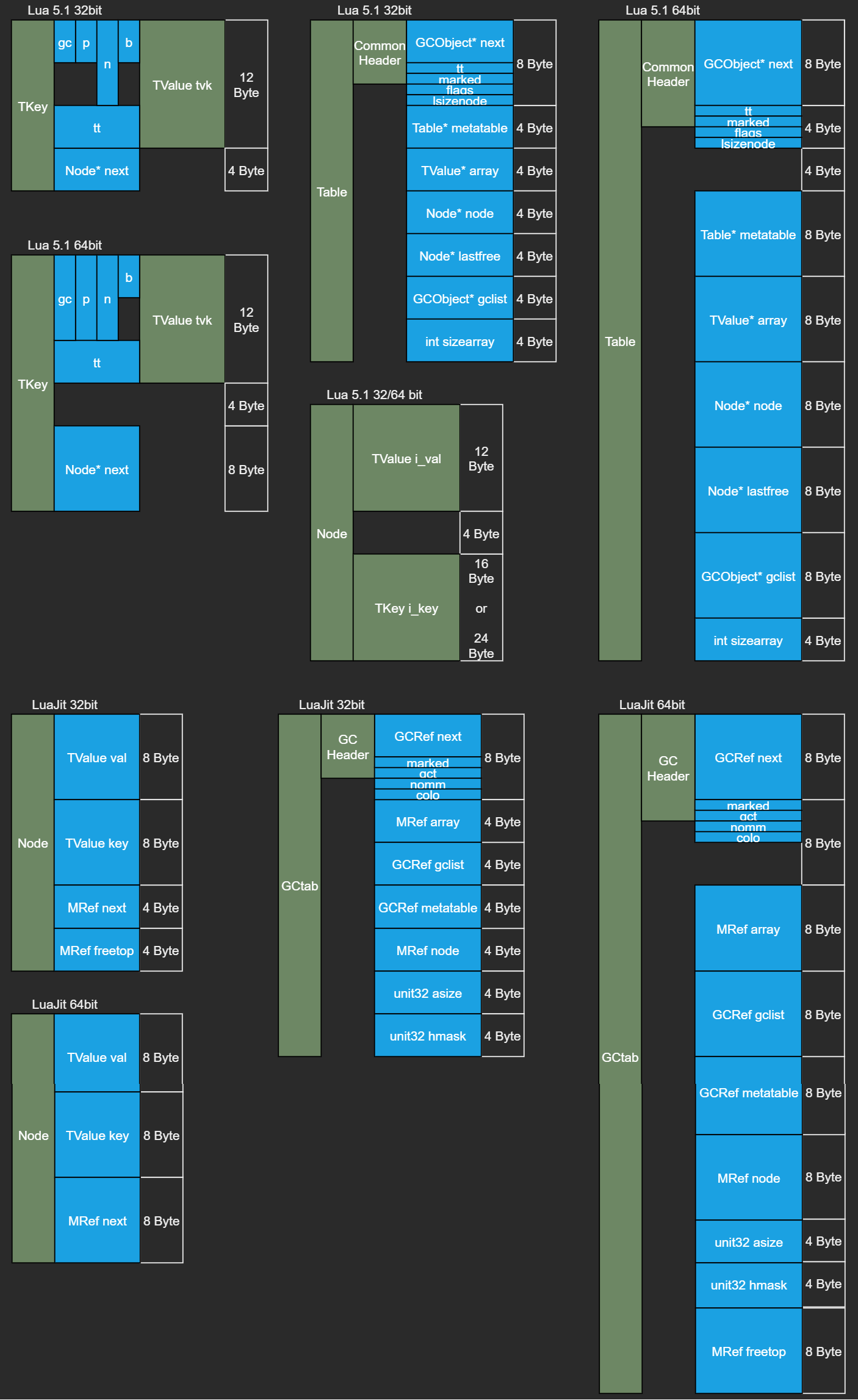
Lua Table的实现相对复杂,具体布局见附录中图表。Table跟其他GCObject类型类似,都有一个CommonHeader,GCObject* next用来把所有需要GC对象链起来存在主线程上。Table的主要成员有Table* metatable,TValue* array,Node* node,Node* lastfree和arraysize记录数组长度,lsizenode记录Hash表大小,lsizenode=log2(sizenode)。
Luajit的Table实现和Lua5.1的实现大同小异,主要的优化点是Luajit的Node使用更紧凑的布局。
在x64中,Lua5.1和Luajit中Table都占64字节,但是Lua5.1 Node占40字节,Luajit Node占24字节。
Lua Hash的实现方法
Lua Hash表会分配长度为2的lsizenode次幂个Node的数组。初始阶段Table.node指向数组起始地址,lastfree指向数组结束地址。当查询指定Key时,由Hash值模数组长度得到Node数组所在index。如果发生碰撞,则将lastfree向前移动直到找到第一个空的位置,并和碰撞位置链起来。[^4]
Lua 5.1中Hash Node数组长度可以为0,而Luajit中Hash Node数组长度最小为1。根据前面分析Node的内存大小,一个Table中Hash表的内存空间就是2的n次幂个乘以Node大小。
必须注意的是,Node数组分配的内存大小虽然会记录到GC total中,但是这段内存是不受GC直接控制的,而是通过GC过程销毁Table时再释放。如果在GC之外,Node数组分配新内存块与释放旧的内存块是及时的,这一点后面再详细讨论。
Lua Array部分的相关技巧
Lua Array部分不是必须存在,如果需要,有两个入口可以构造Array。
- Lua parser阶段直接解析出需要创建的Array size,并在new Table时分配。
- 插入的大量连续整数key时,自动分配Array。具体优化算法见源码ltable.c中reHash函数定义。
Lua Array是TValue类型的连续内存块,Table.arraysize成员来表明该数组的长度。Table.arraysize与脚本中数组长运算符local len = #{}概念不同,可以认为没有直接关系。
Lua Table在引用字段时会先判断TValue key的类型,如果是Lua_Number类型才进一步判断是不是数组下标。Lua 5.1中数组要求Key必须是大于0小于等于arraysize整数,不然就会判定为Hash部分;Luajit则给arraysize分配n+1的空间,来应对0到n的数组下标引用。这里会有一个精度问题,如果想引用的Lua数组下标是通过数值运算来的,那么就要考虑会不会因精度问题而找不到指定的元素。ltable.c文件中luaH_getnum与hashnum相关函数。
Array内存块同Node内存块一样,是及时分配和释放的,但是Array部分比Node部分会小很多,原因是没有显式存储Key值和发生Hash碰撞以后的链表Node* next。Luajit因为TValue大小为8字节,所以Luajit Array部分内存会更加紧凑。但是Luajit存储Array的大小通常是2^n + 1,这一点可能对内存分配器或强迫症患者不太友好。
Table如何动态增长
前文介绍了Table的Array和Hash部分所占空间大小。在通常使用Lua脚本的过程中,我们不会主动确定大小,而是随需要不断插入新的Index或Key。当Table发现Index超出arraysize或这新插入Key时lastfreenode已经没有可用空间了,就会重新确定Table中的Array和Hash部分的大小。这一过程在Lua ltable.c源文件中被定义为rehash。
如前面提过的,Array部分并不是必须要求Table中的值(Val)从下标1(Key)开始连续存储,而是在rehash时通过countint和computesizes函数计算出最佳的Array长度,并把小于arraysize整数Key的Node都移动到Array中。Array中元素的引用也简单高效,不再判断是否发生hash冲突,也不需要频繁考虑是否重新rehash。
Table Array在rehash时除了会积极扩容以外,还会积极缩容。缩容以后不能加入到Array部分中的值会被插入到Hash部分中,反之亦然。
影响Rehash的操作
我原来有个理解误区是,对Table操作,给对于字段赋值nil就是删除一个字段。然而在仔细查阅源码以后发现并不全是这样。
首先对已存在字段赋值nil并不会回收当前node槽位到lastfreenode中。其次每次插入都会检查mainposition(散列时位于Node数组中的直接位置)是否为nil,如果是nil才会重用当前槽位。最后最坏情况下,给一个字段赋值nil仍然会发生rehash操作。
在lvm.c源文件luaV_settable和ltable.c源文件rehash函数中插入打印函数后测试下面脚本:
key1s = {'a1', 'b1', 'c1', 'd1'}
key2s = {'f1', 'g1', 'i1', 'k1'}
print('asignment')
t = {}
for _, k in ipairs(key1s) do
t[k] = 1
end
print('clear')
for k in pairs(t) do
t[k] = nil
end
print('reuse')
for _, k in ipairs(key2s) do
t[k] = 1
end
输出结果为:
asignment
new table cost:0
newkey rehash cost:1 us, asize:0 => 0, hsize:1 => 1, hash count:1
lvm.c SetTable, a1: 0x7fffcc2ad590 => 1.000000!
newkey rehash cost:2 us, asize:0 => 0, hsize:1 => 2, hash count:2
lvm.c SetTable, b1: 0x7fffcc2a6418 => 1.000000!
newkey rehash cost:2 us, asize:0 => 0, hsize:2 => 4, hash count:3
lvm.c SetTable, c1: 0x7fffcc2a4720 => 1.000000!
lvm.c SetTable, d1: 0x7fffcc2a4798 => 1.000000!
clear
lvm.c SetTable, c1: 0x7fffcc2a4720 => nil!
lvm.c SetTable, b1: 0x7fffcc2a4748 => nil!
lvm.c SetTable, a1: 0x7fffcc2a4770 => nil!
lvm.c SetTable, d1: 0x7fffcc2a4798 => nil!
reuse
lvm.c SetTable, f1: 0x7fffcc2a4748 => 1.000000!
lvm.c SetTable, g1: 0x7fffcc2a4720 => 1.000000!
lvm.c SetTable, i1: 0x7fffcc2a4770 => 1.000000!
newkey rehash cost:2 us, asize:0 => 0, hsize:4 => 4, hash count:4
lvm.c SetTable, k1: 0x7fffcc2a7738 => 1.000000!
上面通过打印可以看到当向t插入k1字段时,因为Hash碰撞导致rehash过程。我们还可以构造一个极端的例子:
t = {f=1}
t.a = nil
t.b = nil
t.c = nil
t.d = nil
t.e = nil
从打印输出发现,对Table连续插入nil会导致Table rehash三次:(t = {f=1}是构造行为,在parser时直接确认大小与内存,见lparser.c源文件constructor函数)
new table cost:0
lvm.c SetTable, f: 0x7fffcc2ad590 => 1.000000!
newkey rehash cost:1 us, asize:0 => 0, hsize:1 => 2, hash count:2
lvm.c SetTable, a: 0x7fffcc2a63f0 => nil!
newkey rehash cost:2 us, asize:0 => 0, hsize:2 => 2, hash count:2
lvm.c SetTable, b: 0x7fffcc2a2950 => nil!
lvm.c SetTable, c: 0x7fffcc2a2950 => nil!
newkey rehash cost:1 us, asize:0 => 0, hsize:2 => 2, hash count:2
lvm.c SetTable, d: 0x7fffcc2a63f0 => nil!
lvm.c SetTable, e: 0x7fffcc2a63f0 => nil!
GC标记
上面的例子反应了t.a = nil操作并不一定会释放相关的Node的行为,但是在GC过程中会主动判断当Key对应的Val是nil时,会把该Key标记为Dead Key。(lgc.c源文件中traversetable函数中标记)但是这个操作依然不会恢复lastfreenode。
如果Key值是一个GCObject类型,且是Dead Key,那么它会在当前GC过程中被释放。
Luajit中没有显式标记Dead Key,但是在gc_traverse_tab中没有把值为nil的项标记为还在引用。
时间消耗
上文对Table内存布局的分析中,反复涉及到rehash操作。接下来定量分析一下rehash的耗时。
- 因为运行环境在linux上,所以计时函数使用了
gettimeofday,返回计时单位为微秒(us)。 - 计时范围为ltable.c源文件中单次
newkey函数中只触发rehash部分的逻辑。 - Luajit测量部分类似。
- Luajit虚拟机关闭了jit功能,采用解释执行方式(贴近手机实际使用方式)。
- 本文重点关注一个Table的操作能耗,所以在测试过程中没有使用GCObject类型数据作为Key或Val。
static TValue *newkey(lua_State *L, Table *t, const TValue *key)
{
long start = GetClock();//return us
Node *mp = mainposition(t, key);
if(!ttisnil(gval(mp)) || mp == dummynode)
{
//...
Node *n = getfreepos(t);
if (n == NULL)
{
//...
rehash(L, t, key);
//...
long finish = GetClock();
printf("...", finish - start)
return result;
}
//...
}
//...
}
连续插入的时间消耗
Lua Table在非构造阶段,不论是Array还是Hash部分都是以2的幂次增加的(事实上在构造阶段Hash部分也只能按2的幂次增加)。每当扩容以后,原数据会重新再插入新的内存块中。
Lua API lua_createtable可以指定构造Table的Array个数和Hash Node的个数,但是在脚本中无法直接操作。
下面为测试脚本:
local length = 1000000
local set = {}
local index = {}
local i = 0
while i < length do
local v =math.random(1, length)
if set[v] then
else
i = i + 1
index[i] = v
set[v] = true
end
end
在Table的元素插入的过程中,存在因Lua Table优化算法导致Array部分和Hash部分同时出现的情况。但是这些样本较小,所以主动丢弃了。下图所示数据如果是Array插入,则只筛选hsize == 0 or hsize == 1;如果是Hash插入,则只筛选arraysize == 0。
图中横纵坐标都是对数坐标系。
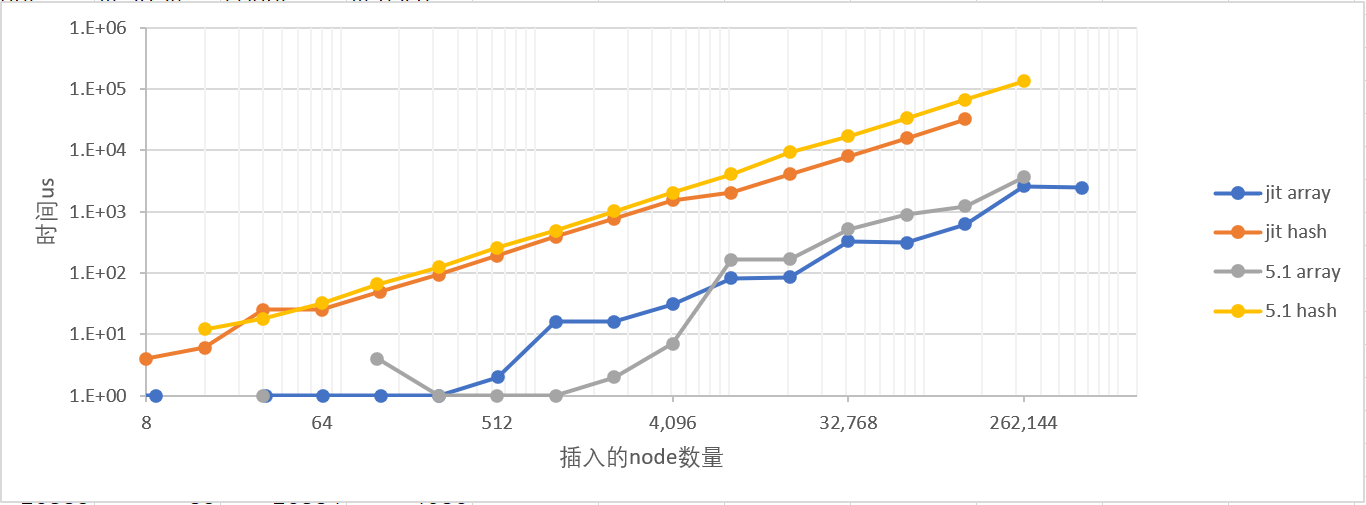
这里横坐标所表示的是插入新Node(Array item)时触发Rehash,所需要重新插入旧Node(Array item)的数量。
从图中可以得到不论是Array还是Node,耗时趋势大体上是随元素数量线性增加的。但是可以明显看到LuaJit和Lua 5.1的Array部分都比Node部分插入时间少将近两个数量级。
等长度插入新Key的时间消耗
除了Table尺寸增加会触发Rehash以外,对于Hash部分,lastfreenode消耗完也会Rehash。(Array不会发生)
为了验证这方面的用时,下面构造一个长度相对稳定的Table,对于超出长度的就删除一些旧的Key,这部分测试数据利用了上面生成的不重复index:
local len = 0
local clear_i = 0
local t = {}
for i, ti in ipairs(index) do
t[ti] = i
len = len + 1
if len > max_len then
for j = 1, max_clear do
local k = clear_i + j
t[index[k]] = nil
end
clear_i = clear_i + max_clear
end
end
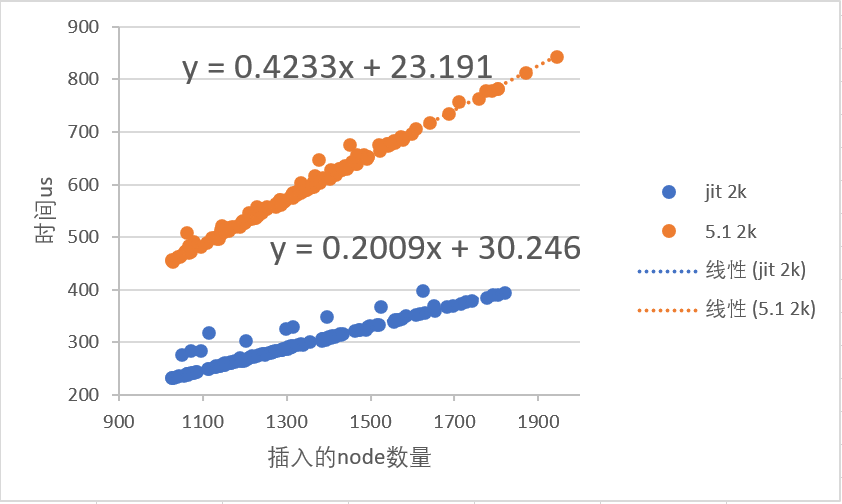
上图横坐标是当lastfreenode == NULL时,需要重新将旧Node内存块上插入新Node内存块上的数量。
线性拟合出LuaJit和Lua 5.1的时间系数,造成这个系数的差距的因素有:
- Node大小在两个虚拟机实现不同,LuaJit/Lua 5.1 = 24 / 40
- LuaJit优化了Table的单次插入函数
lj_tab_set,减少了一次luaH_get调用
总结
- 根据上面测量结果与源码分析,Table Array不仅节省内存,增删查改操作也非常简单高效。接近两个数量级提升。
- Array内存块和Node内存块在rehash时是立即释放的,比起不断新建Table,这样可以一定程度上避免触发GC的概率。
- 大量临时创建长度较短的Table会造成较多的内存碎片,而Lua GC算法不会整理内存碎片,长时间运行以后分配效率可能下降。
附录
Table内存布局
参考
- [1] Lua GC的源码剖析
- [2] Lua GC的工作原理
- [3] Hash部分内部原理
- [4] userdata和light userdata